Echtzeit-Streamverarbeitung mit Apache Flink leicht gemacht
Veröffentlicht am

Die Stream-Verarbeitung in Echtzeit ist zu einem wichtigen Bestandteil der modernen Datenarchitektur geworden. Apache Flink ist ein Open-Source-Framework zur Stream-Verarbeitung, das die Verarbeitung und Analyse von Echtzeitdaten erleichtert. In diesem Blog werden wir untersuchen, wie Apache Flink die Stream-Verarbeitung in Echtzeit vereinfachen kann.
Was ist Apache Flink?

Quelle : educba.com
Apache Flink ist ein Open-Source-Framework für die Stream-Verarbeitung, das eine einheitliche, verteilte Verarbeitungs-Engine für Batch- und Stream-Daten bietet. Es wurde erstmals 2014 von dem Berliner Unternehmen data Artisans entwickelt und später in ein Projekt der Apache Software Foundation überführt. Flink unterstützt eine Vielzahl von Datenquellen, darunter Kafka, Hadoop und Amazon S3, und kann Daten in Echtzeit oder in Batches verarbeiten.
Architektur von Apache Flink
Die Architektur von Apache Flink basiert auf einer verteilten Datenfluss-Engine. Sie besteht aus drei Hauptkomponenten: dem Flink-Cluster, den Flink-Jobs und den Datenquellen/-senken. Der Flink-Cluster ist für die Koordination und Ausführung der Flink-Jobs zuständig, während die Datenquellen/-senken den Zugriff auf die zu verarbeitenden Daten ermöglichen. Flink-Jobs sind die eigentlichen Verarbeitungseinheiten, die Transformationen an den Daten durchführen.
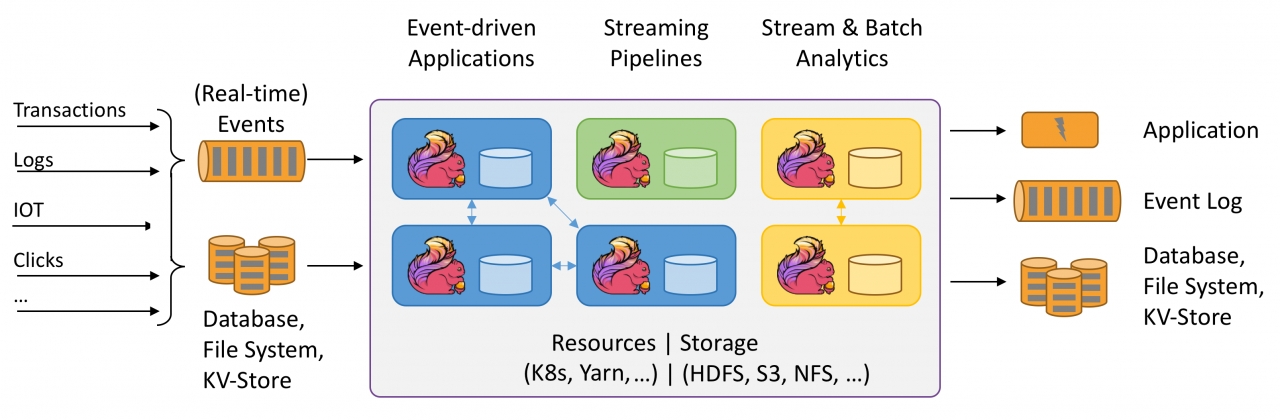
Eigenschaften von Apache Flink
Quelle : itwire.com
Apache Flink verfügt über zahlreiche Funktionen, die es zu einer attraktiven Wahl für die Stream-Verarbeitung in Echtzeit machen. Eine der wichtigsten Funktionen ist die Verarbeitung mit niedriger Latenz. Flink kann Daten in Echtzeit verarbeiten, wobei die Latenzzeiten nur wenige Millisekunden betragen. Flink bietet außerdem eine Vielzahl von APIs für die Datenverarbeitung, einschließlich Batch- und Stream-Verarbeitung, maschinelles Lernen und Graphverarbeitung. Darüber hinaus unterstützt Flink die zustandsbehaftete Stream-Verarbeitung, so dass Sie den Zustand über Datenströme hinweg beibehalten können.
Anwendungsfälle von Apache Flink
Apache Flink kann für eine Vielzahl von Anwendungsfällen eingesetzt werden, darunter Echtzeit-Analysen, Betrugserkennung und Empfehlungssysteme. Ein gängiger Anwendungsfall ist die Echtzeitanalyse, bei der Flink zur Analyse von Streaming-Daten in Echtzeit und zur Bereitstellung von Erkenntnissen für Geschäftsanwender verwendet werden kann. Flink kann auch zur Betrugserkennung eingesetzt werden, indem es Transaktionsdaten in Echtzeit analysiert und betrügerisches Verhalten erkennt. Und schließlich kann Flink für Empfehlungssysteme verwendet werden, bei denen es Benutzerdaten in Echtzeit verarbeitet und personalisierte Empfehlungen bereitstellt.
Erste Schritte mit Apache Flink

Quelle : data-flair.training
Die ersten Schritte mit Apache Flink sind relativ einfach. Der erste Schritt besteht darin, einen Flink-Cluster einzurichten. Sie können entweder einen Flink-Cluster auf Ihren eigenen Servern einrichten oder einen verwalteten Flink-Dienst eines Cloud-Anbieters nutzen. Sobald Sie einen Flink-Cluster eingerichtet haben, können Sie damit beginnen, Flink-Aufträge mithilfe der Flink-APIs oder einer der vielen verfügbaren Bibliotheken zu erstellen.
Schlussfolgerung:
Zusammenfassend lässt sich sagen, dass Apache Flink ein leistungsfähiges Framework für die Stream-Verarbeitung in Echtzeit ist. Es bietet eine einheitliche, verteilte Verarbeitungs-Engine für Batch- und Stream-Daten und unterstützt eine breite Palette von Datenquellen. Flink wurde für eine Verarbeitung mit geringer Latenz, zustandsabhängige Stream-Verarbeitung und umfangreiche APIs für die Datenverarbeitung entwickelt. Wenn Sie Ihre Stream-Verarbeitung in Echtzeit vereinfachen möchten, ist Apache Flink definitiv eine Überlegung wert.








