Alles was du über Hadoop wissen musst
Veröffentlicht am
Hadoop ist eine Open-Source-Software, die für die Speicherung und Verarbeitung großer Datenmengen (Big Data) auf Clustern von Computern verwendet wird. Das Hadoop-Framework besteht aus zwei Hauptkomponenten: Hadoop Distributed File System (HDFS) und Hadoop MapReduce.
Das HDFS ist ein verteiltes Dateisystem, das es ermöglicht, Daten auf einem Cluster von Computern zu speichern und zu verwalten. Es ermöglicht auch die Skalierung von Speicher- und Rechenleistung durch Hinzufügen weiterer Computer zum Cluster.
MapReduce ist ein Programmiermodell für die parallele Verarbeitung von großen Datenmengen auf einem Hadoop-Cluster. Es ermöglicht die Aufteilung von Aufgaben in kleinere Teilprobleme, die auf verschiedenen Knoten im Cluster ausgeführt werden können, und sammelt dann die Ergebnisse zusammen.
Hadoop wird häufig von Unternehmen und Organisationen eingesetzt, um Datenanalyse, Datenverarbeitung und andere Big-Data-Anwendungen durchzuführen.
Wo wird Hadoop verwendet?

Quelle : opencirrus.org
Hadoop wird in verschiedenen Branchen und Anwendungsfällen eingesetzt, in denen große Datenmengen verarbeitet werden müssen. Hier sind einige Beispiele:
- E-Commerce: Unternehmen wie Amazon und eBay verwenden Hadoop zur Analyse von Kundendaten und zur Optimierung von Marketingstrategien.
- Finanzwesen: Banken und Finanzinstitute setzen Hadoop ein, um Risikoanalysen durchzuführen, Betrug aufzudecken und Compliance-Regeln einzuhalten.
- Gesundheitswesen: Hadoop wird verwendet, um medizinische Daten zu verwalten, Patientendaten zu analysieren und die Wirksamkeit von Behandlungen zu bewerten.
- Telekommunikation: Telekommunikationsunternehmen verwenden Hadoop zur Analyse von Netzwerkdaten und zur Verbesserung der Netzwerkleistung.
- Energiewirtschaft: Unternehmen im Bereich der erneuerbaren Energien setzen Hadoop zur Optimierung von Stromnetzen und zur Vorhersage von Stromverbrauch ein.
Diese Liste ist jedoch bei weitem nicht vollständig. Hadoop kann in fast jeder Branche eingesetzt werden, in der große Datenmengen verarbeitet werden müssen.
Wie schwierig ist es Hadoop zu verwenden?
Quelle : syntrixconsulting.com
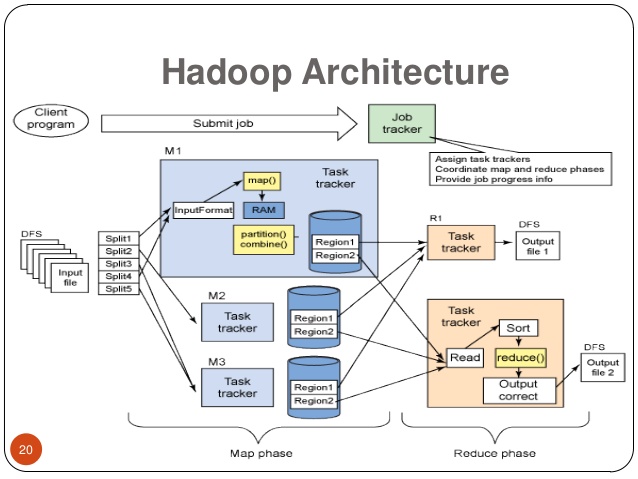
Die Verwendung von Hadoop erfordert ein gewisses Maß an technischer Kenntnisse und Erfahrung, insbesondere wenn es um die Einrichtung, Konfiguration und Verwaltung eines Hadoop-Clusters geht. Ein grundlegendes Verständnis von Linux-Systemen und Netzwerkprotokollen sowie Kenntnisse in Programmiersprachen wie Java sind ebenfalls von Vorteil.
Darüber hinaus erfordert die Programmierung von Hadoop-Anwendungen Kenntnisse in MapReduce-Programmierung und Hadoop-Ökosystemtechnologien wie HBase, Pig, Hive und Spark.
Aufgrund der Komplexität und der spezialisierten Kenntnisse kann die Verwendung von Hadoop für Einsteiger schwierig sein. Es gibt jedoch viele Ressourcen, Tutorials und Schulungen, die verfügbar sind, um Einsteigern den Einstieg in die Verwendung von Hadoop zu erleichtern.
Wieso sollte man Hadoop für Big Data verwenden?
Quelle : commons.wikimedia.org
Es gibt mehrere Gründe, warum Hadoop für Big Data-Verarbeitung verwendet wird:
- Skalierbarkeit: Hadoop ist auf die Verarbeitung großer Datenmengen ausgelegt und kann problemlos auf Tausende von Knoten in einem Cluster skalieren. Dies ermöglicht es, große Datenmengen zu speichern und zu verarbeiten, die auf einem einzelnen Computer nicht verarbeitet werden können.
- Wirtschaftlichkeit: Hadoop ist eine Open-Source-Software und kann auf kostengünstiger Hardware betrieben werden, was es Unternehmen ermöglicht, große Datenmengen zu speichern und zu verarbeiten, ohne teure proprietäre Systeme kaufen zu müssen.
- Flexibilität: Hadoop kann sowohl strukturierte als auch unstrukturierte Daten speichern und verarbeiten. Es kann auch mit verschiedenen Datenquellen und -formaten arbeiten, einschließlich relationale Datenbanken, NoSQL-Datenbanken, Social-Media-Daten und Sensordaten.
- Datensicherheit: Hadoop bietet integrierte Sicherheitsfunktionen wie Zugriffskontrollen, Verschlüsselung und Auditing, um sicherzustellen, dass Daten sicher gespeichert und verarbeitet werden.
- Datenanalyse: Hadoop enthält Tools wie Hive, Pig und Spark, die für die Datenanalyse und -verarbeitung entwickelt wurden und es ermöglichen, komplexe Abfragen und Analysen auf großen Datenmengen durchzuführen.
Insgesamt bietet Hadoop eine kostengünstige, skalierbare und flexible Lösung für die Speicherung und Verarbeitung von Big Data, was es zu einer beliebten Wahl für Unternehmen und Organisationen macht, die große Datenmengen verarbeiten müssen.
Was ist der Unterschied zwischen Spark und Hadoop?

Quelle : logowik.com
Spark und Hadoop sind beide Open-Source-Software-Tools, die für die Verarbeitung großer Datenmengen verwendet werden. Es gibt jedoch einige Unterschiede zwischen den beiden:
- Verarbeitungsgeschwindigkeit: Spark ist in der Regel schneller als Hadoop, da es die Daten im Hauptspeicher verarbeitet, während Hadoop die Daten auf die Festplatte schreibt und liest. Spark wurde auch für die Verarbeitung von Echtzeit-Datenströmen optimiert.
- Speicherverwaltung: Spark verfügt über eine integrierte Speicherverwaltung, die es ihm ermöglicht, Daten im Arbeitsspeicher zu halten und bei Bedarf auszulagern, während Hadoop Daten nur auf Festplatten speichert.
- Datenverarbeitung: Hadoop wurde für die Batch-Verarbeitung großer Datenmengen entwickelt, während Spark für die Verarbeitung von Streaming-Daten und interaktiven Abfragen optimiert wurde.
- Programmiermodelle: Hadoop verwendet das MapReduce-Modell für die Datenverarbeitung, während Spark ein allgemeines Cluster-Computing-Modell verwendet, das als Resilient Distributed Datasets (RDDs) bezeichnet wird.
- Ökosystem: Beide Tools haben ein umfangreiches Ökosystem von Erweiterungen und Tools. Hadoop verfügt über HBase, Hive, Pig und andere Tools, während Spark ein breites Spektrum von Erweiterungen und APIs hat, die mit verschiedenen Datenquellen und -formaten arbeiten können.
Zusammenfassend lässt sich sagen, dass Spark in der Regel schneller und besser für die Verarbeitung von Streaming-Daten und interaktiven Abfragen geeignet ist, während Hadoop besser für die Batch-Verarbeitung großer Datenmengen geeignet ist. Allerdings ergänzen sich beide Tools sehr gut und werden oft zusammen verwendet, um die Vorteile beider Systeme zu nutzen.








