Was ist Unsupervised Learning?
Veröffentlicht am

Unsupervised Learning ist eine Form des Machine Learnings, bei der ein Algorithmus Muster in Daten entdeckt, ohne dass ihm im Voraus bekannte Beispiele oder Labels vorgegeben werden. Im Gegensatz zum Supervised Learning, bei dem das Modell trainiert wird, um Vorhersagen auf der Grundlage von bekannten Beispielen zu treffen, muss das Modell im Unsupervised Learning selbständig Muster und Zusammenhänge in den Daten finden.
In der Praxis kann Unsupervised Learning verwendet werden, um beispielsweise Cluster oder Gruppen in einem Datensatz zu identifizieren, die Ähnlichkeiten aufweisen. Es kann auch eingesetzt werden, um Muster in den Daten zu entdecken, die auf Abweichungen oder Anomalien hinweisen. Darüber hinaus kann Unsupervised Learning auch dazu verwendet werden, Daten zu reduzieren oder zu komprimieren, um die Datenverarbeitung und -speicherung zu vereinfachen.
Ein Beispiel für Unsupervised Learning ist das Clustering, bei dem Daten in Gruppen basierend auf ihrer Ähnlichkeit zusammengefasst werden. Ein weiteres Beispiel ist die Dimensionsreduktion, bei der der Datensatz so transformiert wird, dass er in einem niedrigeren Dimensionsraum dargestellt werden kann, ohne dass wichtige Informationen verloren gehen.
Unsupervised Learning ist in vielen Anwendungsbereichen nützlich, insbesondere wenn es darum geht, verborgene Muster und Zusammenhänge in großen und komplexen Datensätzen zu identifizieren. Es ist jedoch auch schwieriger als Supervised Learning, da es schwieriger ist, die Ergebnisse zu validieren und zu beurteilen, da es keine klaren Labels gibt, die die Richtigkeit der Vorhersagen bestätigen können.
In welchen Bereichen wird Unsupervised Learning angewendet?
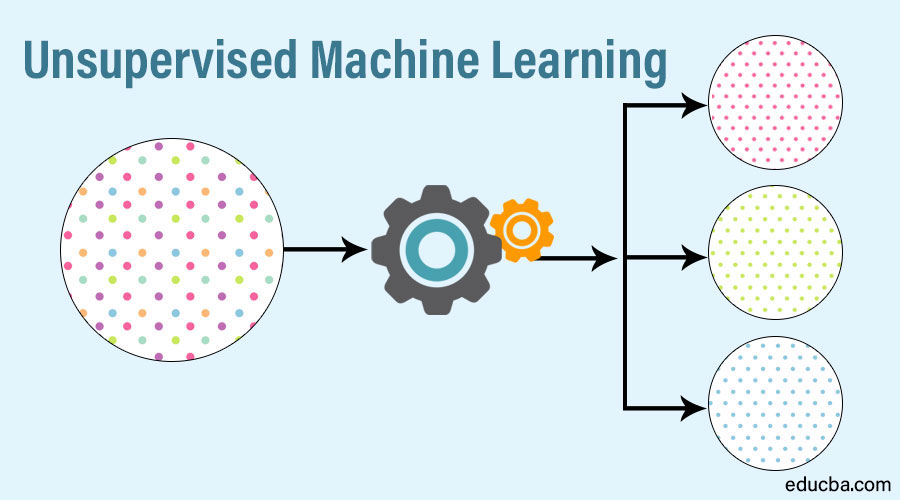
Quelle : educba.com
Unsupervised Learning wird in vielen Anwendungsbereichen eingesetzt, in denen große, komplexe Datenmengen verarbeitet werden müssen, um Muster und Zusammenhänge zu identifizieren. Einige der Anwendungsbereiche von Unsupervised Learning sind:
- Datensegmentierung und -clustering: Das Clustering ist ein wichtiger Anwendungsfall von Unsupervised Learning, bei dem ähnliche Datenpunkte in Gruppen oder Clustern zusammengefasst werden. Dies kann in verschiedenen Bereichen wie Marketing, Medizin, Finanzen oder Mustererkennung eingesetzt werden.
- Anomalieerkennung: Unsupervised Learning kann auch dazu verwendet werden, Abweichungen oder Anomalien in Daten zu erkennen, die auf ungewöhnliche oder potenziell schädliche Ereignisse hinweisen können. Ein Beispiel hierfür ist die Erkennung von Betrug bei Kreditkarten-Transaktionen oder die Erkennung von Netzwerkangriffen.
- Mustererkennung und -generierung: Unsupervised Learning kann dazu beitragen, Muster in Daten zu identifizieren, die sonst schwer zu erkennen wären. Ein Beispiel hierfür ist die Generierung von Bildern oder Texten basierend auf vorhandenen Daten, ohne dass menschliche Interaktion erforderlich ist.
- Empfehlungssysteme: Unsupervised Learning kann dazu beitragen, Ähnlichkeiten zwischen Nutzern und Produkten zu identifizieren, um personalisierte Empfehlungen zu generieren. Ein Beispiel hierfür sind Empfehlungssysteme in E-Commerce-Plattformen oder Streaming-Diensten.
- Reduktion der Dimensionalität: Unsupervised Learning kann dazu verwendet werden, die Dimensionalität von Daten zu reduzieren, um die Datenverarbeitung und -speicherung zu vereinfachen. Ein Beispiel hierfür ist die Verwendung von PCA (Principal Component Analysis) zur Reduktion der Dimensionalität von Bildern oder anderen hochdimensionalen Daten.
Wofür eignet sich Unsupervised Learning nicht?

Quelle : enjoyalgorithms.com
Unsupervised Learning ist in der Lage, komplexe Datenmuster zu entdecken, ohne dass eine menschliche Supervision erforderlich ist. Es eignet sich jedoch nicht für alle Aufgaben im Bereich des maschinellen Lernens. Einige der Einschränkungen von Unsupervised Learning sind:
- Labeling von Daten: Da Unsupervised Learning keine vorgegebenen Labels verwendet, kann es schwierig sein, die gefundenen Muster und Gruppierungen zu interpretieren oder zu verstehen. Dies ist insbesondere dann der Fall, wenn die Daten sehr komplex sind oder es viele Faktoren gibt, die die Muster beeinflussen.
- Überwachtes Lernen: In einigen Fällen ist überwachtes Lernen effektiver, da es spezifische Labels verwendet, um das Modell zu trainieren. Zum Beispiel kann Supervised Learning genauer sein, wenn es darum geht, eine bestimmte Klasse von Objekten zu identifizieren oder Vorhersagen über zukünftige Ereignisse zu treffen.
- Kontrolle des Outputs: Bei Unsupervised Learning besteht die Gefahr, dass das Modell unerwünschte oder nicht-intuitive Ergebnisse produziert, da es aufgrund fehlender Labels keine klaren Vorgaben erhält. In einigen Anwendungsbereichen, wie der medizinischen Diagnose oder der Identifikation von Sicherheitsrisiken, kann dies ein ernsthaftes Problem darstellen.
- Berechnungsaufwand: Unsupervised Learning kann sehr rechenaufwendig sein, insbesondere wenn große Datenmengen verarbeitet werden müssen. Die Verwendung von Parallelisierungstechniken und leistungsstarken Hardware-Ressourcen kann dazu beitragen, diesen Aufwand zu reduzieren, aber in einigen Fällen kann es dennoch unpraktisch sein.
- Skalierbarkeit: Die Skalierung von Unsupervised Learning-Modellen kann schwierig sein, da es schwierig sein kann, die Relevanz und Qualität der Ergebnisse zu beurteilen, wenn die Datenmengen sehr groß werden. Hier kann Supervised Learning oft besser skalieren, da es auf klare Ziele und Vorgaben ausgerichtet ist.
Welches sind die bekanntesten Techniken, welche in Unsupervised Learning angewendet werden?
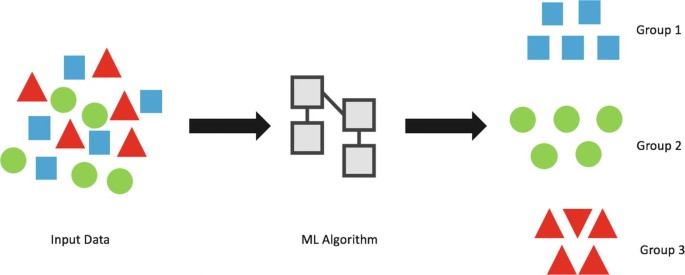
Quelle : link.springer.com
Unsupervised Learning umfasst eine Vielzahl von Techniken und Methoden, um Muster und Strukturen in Daten zu entdecken, ohne dass eine menschliche Supervision erforderlich ist. Einige der bekanntesten Techniken sind:
- Clusteranalyse: Hierbei werden Datenpunkte in Gruppen oder Clustern gruppiert, basierend auf gemeinsamen Merkmalen und Ähnlichkeiten.
- Dimensionsreduktion: Ziel ist es, eine hohe Anzahl an Merkmalen auf eine geringere Anzahl an Dimensionen zu reduzieren, ohne dabei Informationen zu verlieren. Hierfür gibt es verschiedene Ansätze, wie z.B. PCA (Principal Component Analysis) oder t-SNE (t-Distributed Stochastic Neighbor Embedding).
- Assoziationsregeln: Diese Technik findet Zusammenhänge zwischen Attributen oder Ereignissen in Daten und wird oft im Bereich der Marktanalyse oder beim Empfehlungssystemen eingesetzt.
- Anomalieerkennung: Hierbei wird versucht, Ausreißer oder Anomalien in Daten zu identifizieren, die von der normalen Verteilung abweichen.
- Generative Modelle: Mit generativen Modellen wird versucht, eine Wahrscheinlichkeitsverteilung der Daten zu modellieren, um beispielsweise neue Daten generieren oder fehlende Daten interpolieren zu können.
Diese Techniken können in verschiedenen Anwendungsbereichen eingesetzt werden, wie z.B. der Bildverarbeitung, der Sprachverarbeitung, der Biomedizin und der Finanzanalyse.
Welche Jobs existieren für Spezialisten in Unsupervised Learning?
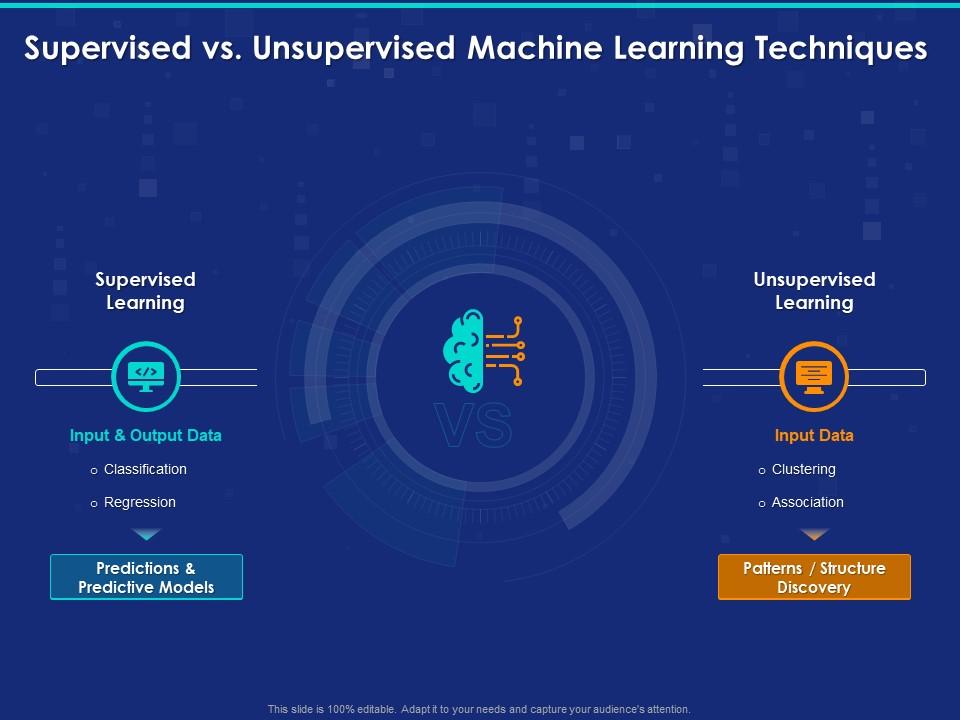
Quelle : slideteam.net
Es gibt eine Vielzahl von Jobmöglichkeiten für Spezialisten im Bereich Unsupervised Learning. Einige Beispiele sind:
- Data Scientist: Ein Data Scientist arbeitet daran, Datensätze zu analysieren, um Erkenntnisse und Vorhersagen zu gewinnen. Hierbei kommt Unsupervised Learning zum Einsatz, um Muster und Strukturen in den Daten zu erkennen.
- Machine Learning Engineer: Ein Machine Learning Engineer ist für die Entwicklung und Implementierung von Machine-Learning-Algorithmen und -Modellen verantwortlich. Hierbei kann sowohl Supervised als auch Unsupervised Learning zum Einsatz kommen.
- Business Intelligence Analyst: Ein Business Intelligence Analyst verwendet Datenanalyse-Tools und -Techniken, um Unternehmen bei Entscheidungen zu unterstützen. Hierbei kommt Unsupervised Learning zum Einsatz, um Zusammenhänge in den Daten zu entdecken und Vorhersagen zu treffen.
- Data Mining Specialist: Ein Data Mining Specialist ist auf die Extraktion von Mustern und Erkenntnissen aus großen Datenmengen spezialisiert. Hierbei kann Unsupervised Learning verwendet werden, um unbekannte Muster in den Daten zu entdecken.
- Research Scientist: Ein Research Scientist arbeitet daran, neue Machine-Learning-Methoden und -Technologien zu entwickeln. Hierbei kann Unsupervised Learning eine wichtige Rolle spielen, um neue Techniken zur Mustererkennung und -analyse zu entwickeln.
Diese Liste ist natürlich nicht erschöpfend, da Unsupervised Learning in vielen Bereichen der Datenauswertung eingesetzt wird und daher auch eine Vielzahl von Jobmöglichkeiten bietet.



