Real-time stream processing made easy with Apache Flink
Published

Real-time stream processing has become an important part of modern data architecture. Apache Flink is an open source stream processing framework that makes it easier to process and analyze real-time data. In this blog, we will explore how Apache Flink can simplify real-time stream processing.
What is Apache Flink?

Those : educba.com
Apache Flink is an open source stream processing framework that provides a unified, distributed processing engine for batch and stream data. It was first developed in 2014 by the Berlin company data Artisans and later transferred to a project by the Apache Software Foundation. Flink supports a variety of data sources, including Kafka, Hadoop, and Amazon S3, and can process data in real-time or batches.
Apache Flink architecture
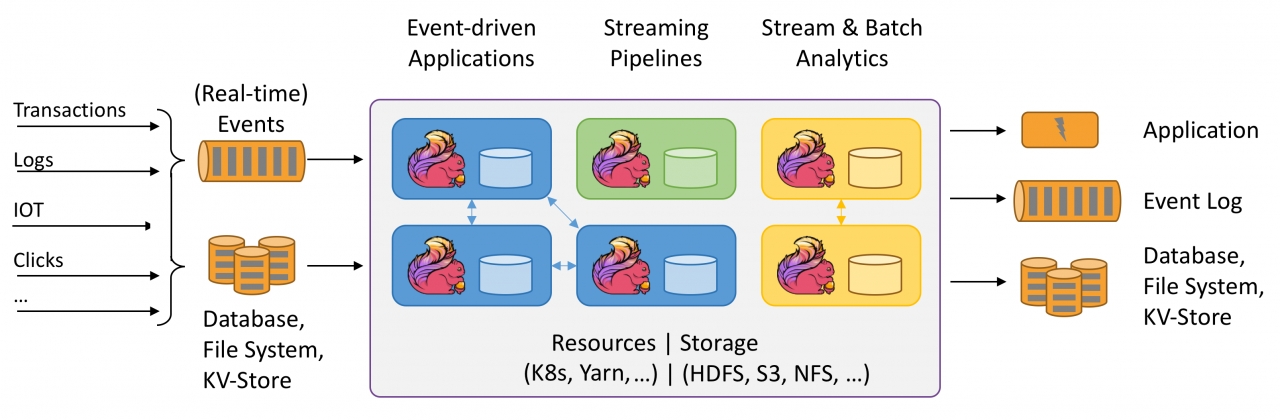
Apache Flink's architecture is based on a distributed data flow engine. It consists of three main components: the Flink cluster, the Flink jobs and the data sources/sinks. The Flink cluster is responsible for coordinating and executing the Flink jobs, while the data sources/sinks provide access to the data to be processed. Flink jobs are the actual processing units that perform transformations on the data.
Properties of Apache Flink
Those : itwire.com
Apache Flink has numerous features that make it an attractive choice for real-time stream processing. One of the most important features is low latency processing. Flink can process data in real time, with latency times as low as a few milliseconds. Flink also offers a variety of APIs for data processing, including batch and stream processing, machine learning, and graph processing. Additionally, Flink supports stateful stream processing, allowing you to maintain state across data streams.
Apache Flink use cases
Apache Flink can be used for a variety of use cases including real-time analytics, fraud detection, and recommendation systems. A common use case is real-time analytics, where Flink can be used to analyze streaming data in real-time and provide insights to business users. Flink can also be used for fraud detection by analyzing transaction data in real-time and detecting fraudulent behavior. Finally, Flink can be used for recommendation systems, where it processes user data in real time and provides personalized recommendations.
Getting started with Apache Flink

Those : data-flair.training
The first steps with Apache Nimble are relatively simple. The first step is to set up a Flink cluster. You can either set up a Flink cluster on your own servers or use a managed Flink service from a cloud provider. Once you have a Flink cluster set up, you can begin creating Flink jobs using the Flink APIs or one of the many available libraries.
Conclusion:
In summary, Apache Flink is a powerful framework for real-time stream processing. It provides a unified, distributed processing engine for batch and stream data and supports a wide range of data sources. Flink is designed for low latency processing, stateful stream processing, and rich APIs for data processing. If you want to simplify your stream processing in real time, Apache Flink is definitely worth considering.








