The Power of Apache Kafka: Streamlining Real-Time Data Processing
Published

In today's digital world, real-time data processing is becoming increasingly important for companies to remain competitive. Apache Kafka is an open source distributed event streaming platform that allows you to stream data in real time. In this blog, we will explore the power of Apache Kafka and how it can streamline real-time data processing.
What is Apache Kafka?

Those : kai-waehner.de
Apache Kafka is a distributed streaming platform that allows you to publish and subscribe to streams. It was first developed by LinkedIn in 2011 and later became an open source project by the Apache Software Foundation. Kafka is designed to process large amounts of data in real-time and can be used for a variety of use cases such as data pipelines, real-time analytics, and event-driven architectures.
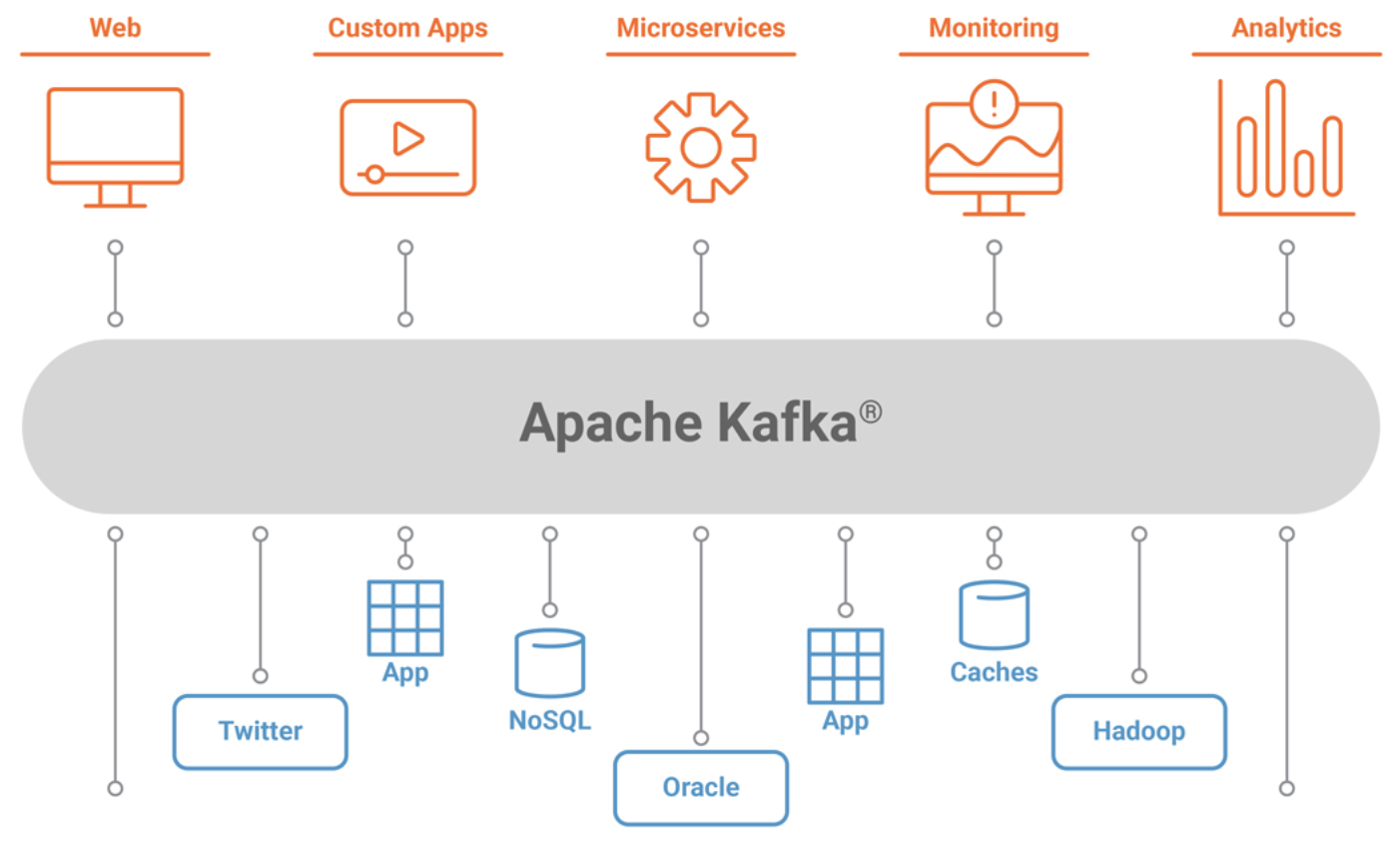
Apache Kafka architecture
Apache Kafka's architecture is based on the publish-subscribe model. It consists of three main components: producers, subjects and consumers. Producers are responsible for publishing records to a topic, while consumers subscribe to and receive records from a topic. Kafka brokers act as message brokers between producers and consumers, ensuring that data is distributed in a fault-tolerant and scalable manner.
Apache Kafka use cases

Those : kafka.apache.org
Apache Kafka can be used for a wide range of use cases. A common use case is building data pipelines. Kafka can be used to transfer data between different systems and applications in real time. Another use case is real-time analytics. Kafka can be used to push data to analytics systems in real time, allowing companies to make data-driven decisions faster. Kafka can also be used for event-driven architectures, where applications are triggered by events in real time.
Advantages of Apache Kafka
One of the main advantages of Apache Kafka is its scalability. Kafka can process large amounts of data and easily scales horizontally to handle increasing loads. Kafka is also fault-tolerant, ensuring that no data is lost in the event of failures. Another advantage of Kafka is its low latency. Kafka is designed for real-time data processing and can deliver data to consumers in real-time, making it an ideal choice for use cases such as real-time analytics.
Getting started with Apache Kafka
Those : davidxiang.com
The first steps with Apache Kafka are relatively simple. The first step is to set up a Kafka cluster. You can either set up a Kafka cluster on your own servers or use a managed Kafka service from a cloud provider. Once you have a Kafka cluster set up, you can begin producing and consuming data using the Kafka API or one of the many available client libraries.
Conclusion:
To summarize, Apache Kafka is a powerful platform for real-time data processing. It enables real-time streaming of data, making it ideal for a variety of use cases such as data pipelines, real-time analytics, and event-driven architectures. Kafka is designed for scalability, fault tolerance, and low latency, making it a popular choice for companies of all sizes. If you want to optimize your real-time data processing, Apache Kafka is definitely worth considering.








