Everything you need to know about Hadoop
Published
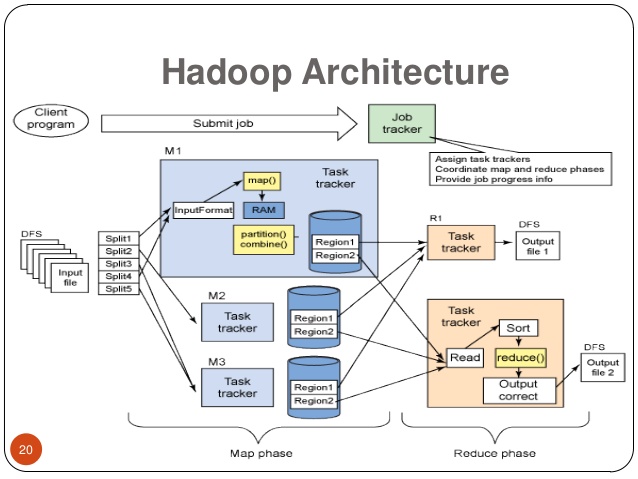
Hadoop is an open source software used for storing and processing large amounts of data (big data) on clusters of computers. The Hadoop framework consists of two main components: Hadoop Distributed File System (HDFS) and Hadoop MapReduce.
The HDFS is a distributed file system that allows data to be stored and managed on a cluster of computers. It also allows storage and computing power to be scaled by adding more computers to the cluster.
MapReduce is a programming model for parallel processing of large amounts of data on a Hadoop cluster. It allows tasks to be broken down into smaller sub-problems that can be run on different nodes in the cluster and then aggregates the results together.
Hadoop is widely used by companies and organizations to perform data analysis, data processing, and other big data applications.
Where is Hadoop used?

Those : opencirrus.org
Hadoop is used in various industries and use cases that require processing large amounts of data. Here are some examples:
- E-commerce: Companies like Amazon and eBay use Hadoop to analyze customer data and optimize marketing strategies.
- Finance: Banks and financial institutions use Hadoop to perform risk analysis, detect fraud, and meet compliance regulations.
- Healthcare: Hadoop is used to manage medical data, analyze patient data, and evaluate the effectiveness of treatments.
- Telecommunications: Telecommunications companies use Hadoop to analyze network data and improve network performance.
- Energy industry: Renewable energy companies use Hadoop to optimize power grids and predict power consumption.
However, this list is far from complete. Hadoop can be used in almost any industry that requires processing large amounts of data.
How difficult is it to use Hadoop?
Those : syntrixconsulting.com
Using Hadoop requires a certain level of technical knowledge and experience, especially when it comes to setting up, configuring, and managing a Hadoop cluster. A basic understanding of Linux systems and network protocols as well as knowledge of programming languages such as Java are also beneficial.
Additionally, programming Hadoop applications requires knowledge of MapReduce programming and Hadoop ecosystem technologies such as HBase, Pig, Hive, and Spark.
Due to its complexity and specialized knowledge, Hadoop can be difficult to use for beginners. However, there are many resources, tutorials, and training available to help beginners get started using Hadoop.
Why use Hadoop for Big Data?
Those : commons.wikimedia.org
There are several reasons why Hadoop is used for big data processing:
- Scalability: Hadoop is designed to handle large amounts of data and can easily scale to thousands of nodes in a cluster. This makes it possible to store and process large amounts of data that cannot be processed on a single computer.
- Economics: Hadoop is open source software and can run on inexpensive hardware, allowing companies to store and process large amounts of data without having to purchase expensive proprietary systems.
- Flexibility: Hadoop can store and process both structured and unstructured data. It can also work with various data sources and formats, including relational databases, NoSQL databases, social media data and sensor data.
- Data Security: Hadoop provides built-in security features such as access controls, encryption, and auditing to ensure data is stored and processed securely.
- Data Analysis: Hadoop includes tools such as Hive, Pig, and Spark that are designed for data analysis and processing, allowing complex queries and analysis to be performed on large amounts of data.
Overall, Hadoop offers a cost-effective, scalable, and flexible solution for big data storage and processing, making it a popular choice for companies and organizations that need to process large amounts of data.
What is the difference between Spark and Hadoop?

Those : logowik.com
Spark and Hadoop are both open source software tools used for processing large amounts of data. However, there are some differences between the two:
- Processing speed: Spark is typically faster than Hadoop because it processes the data in main memory while Hadoop writes and reads the data to disk. Spark has also been optimized for processing real-time data streams.
- Memory management: Spark has built-in memory management that allows it to keep data in memory and swap it out when needed, while Hadoop only stores data on disk.
- Data Processing: Hadoop is designed for batch processing large amounts of data, while Spark is optimized for processing streaming data and interactive queries.
- Programming Models: Hadoop uses the MapReduce model for data processing, while Spark uses a general cluster computing model called Resilient Distributed Datasets (RDDs).
- Ecosystem: Both tools have an extensive ecosystem of extensions and tools. Hadoop has HBase, Hive, Pig and other tools, while Spark has a wide range of extensions and APIs that can work with different data sources and formats.
In summary, Spark is typically faster and better suited to processing streaming data and interactive queries, while Hadoop is better suited to batch processing large amounts of data. However, both tools complement each other very well and are often used together to take advantage of the benefits of both systems.








