Die Kunst der Kompilierung: Alles, was Sie wissen müssen
Veröffentlicht am
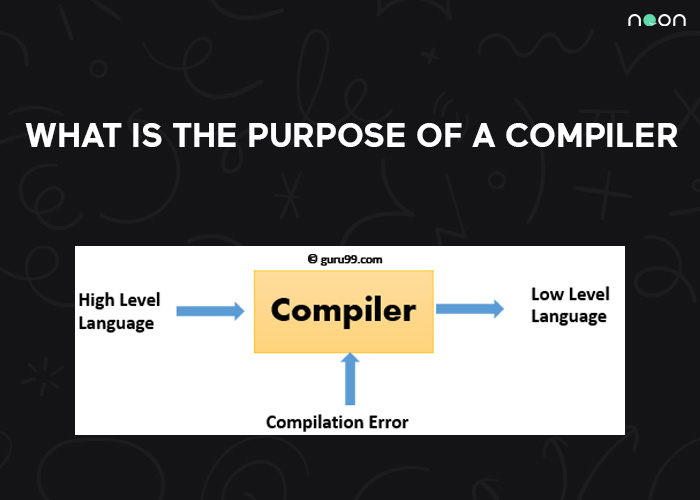
Grundlagen der Kompilierung: Eine Einführung
Die Kompilierung ist ein essentieller Prozess in der Welt der Softwareentwicklung, der den Übergang von menschenlesbarem Quellcode zu ausführbarem Maschinencode ermöglicht. Sie bildet das Rückgrat der meisten modernen Programmiersprachen und stellt sicher, dass unsere Anwendungen auf verschiedenen Plattformen und Systemen funktionieren. Bei der Kompilierung wird der Quellcode von einem Compiler analysiert und in eine Zwischendarstellung übersetzt, die oft als Objektcode bezeichnet wird. Dieser Objektcode wird dann weiter verarbeitet, um den endgültigen Maschinencode zu erzeugen, den der Computer ausführen kann.
Der Kompilierungsprozess ermöglicht Entwicklern, flexibel in Hochsprachen wie C++, Java oder Python zu codieren, ohne sich um die spezifische Hardware oder Architektur eines Zielsystems sorgen zu müssen. Es ist dieser Übersetzungsschritt, der die Portabilität von Software gewährleistet, da der gleiche Quellcode auf verschiedenen Plattformen verwendet werden kann, ohne ihn neu schreiben zu müssen. Darüber hinaus bietet die Kompilierung auch den Vorteil der Codeoptimierung, wodurch Programme schneller und effizienter ausgeführt werden können.
Im weiteren Verlauf dieses Blogs werden wir tief in den Kompilierungsprozess eintauchen, die verschiedenen Phasen des Übersetzens erkunden und die Bedeutung der Kompilierung in der heutigen Softwareentwicklung besser verstehen.
Kompilierungsprozess im Detail: Vom Quellcode zum ausführbaren Programm
Der Kompilierungsprozess ist ein komplexer Vorgang, der den Quellcode in ausführbaren Maschinencode umwandelt. Dieser Prozess kann grob in mehrere Phasen unterteilt werden, die im Folgenden näher erläutert werden:
- Lexikalische Analyse: In dieser Phase wird der Quellcode in einzelne Token aufgeteilt. Dabei werden auch Kommentare entfernt und Zeilenenden standardisiert. Dieser Schritt bereitet den Code für die weitere Verarbeitung vor.
- Syntaxanalyse: Hier wird überprüft, ob die Reihenfolge und Struktur der Tokens den grammatikalischen Regeln der Programmiersprache entsprechen. Dieser Schritt stellt sicher, dass der Code korrekt geschrieben ist.
- Semantische Analyse: In dieser Phase wird der Quellcode auf semantische Fehler überprüft, z. B. ob Variablen deklariert, aber nicht verwendet werden. Diese Analyse gewährleistet, dass der Code sinnvoll ist.
- Codegenerierung: Der Compiler erstellt den Zwischencode, auch bekannt als Objektcode, aus den analysierten und überprüften Quellcode-Dateien. Dieser Objektcode ist plattformunabhängig und enthält Anweisungen, die von der Zielmaschine ausgeführt werden können.
- Linking: Wenn ein Programm aus mehreren Quellcode-Dateien besteht, werden diese in dieser Phase zu einem einzigen ausführbaren Programm verknüpft. Bibliotheken und externe Module werden ebenfalls integriert.
- Optimierung: Optional, aber entscheidend für die Leistung, kann der Compiler den erzeugten Code optimieren. Dies bedeutet, dass der Objektcode so umgeschrieben wird, dass er schneller oder effizienter ausgeführt wird.
Nachdem dieser Prozess abgeschlossen ist, entsteht ein ausführbares Programm, das auf dem Zielcomputer ausgeführt werden kann. Der Kompilierungsprozess ermöglicht es Entwicklern, menschenlesbaren Quellcode in Maschinensprache umzuwandeln und somit Software für verschiedene Plattformen und Architekturen zu erstellen.
Kompilierungsprozess im Detail: Vom Quellcode zum ausführbaren Programm
Der Kompilierungsprozess ist ein entscheidender Schritt in der Softwareentwicklung, bei dem der menschenlesbare Quellcode in ausführbare Maschinenanweisungen umgewandelt wird. Dieser Prozess kann grob in mehrere aufeinanderfolgende Phasen unterteilt werden, die im Detail betrachtet werden müssen:
- Lexikalische Analyse: Diese Phase ist der erste Schritt des Kompilierungsprozesses. Der Quellcode wird in einzelne Lexeme oder Tokens aufgeteilt, wobei Leerzeichen und Zeilenumbrüche entfernt werden. Dadurch wird der Code in eine für den Compiler verständliche Form gebracht.
- Syntaxanalyse: In dieser Phase wird die Grammatik des Quellcodes überprüft. Der Compiler stellt sicher, dass die Anordnung der Tokens den syntaktischen Regeln der Programmiersprache entspricht. Wenn Fehler oder Ungültigkeiten festgestellt werden, wird eine Fehlermeldung generiert.
- Semantische Analyse: Hier wird der Code auf semantische Fehler überprüft. Das bedeutet, dass der Compiler sicherstellt, dass Variablen korrekt deklariert und verwendet werden, und dass alle Verweise auf Funktionen und Objekte sinnvoll sind.
- Codegenerierung: In dieser Phase wird der Quellcode in den Zwischencode oder in den sogenannten Objektcode übersetzt. Dieser Zwischencode ist plattformunabhängig und enthält Anweisungen, die von der Zielmaschine verstanden werden.
- Optimierung: Bei Bedarf können Compiler auch Optimierungen am erzeugten Code vornehmen. Dies umfasst beispielsweise die Entfernung nicht verwendeter Variablen oder die Umstellung von Anweisungen, um die Leistung zu verbessern.
- Linking: Wenn ein Programm aus mehreren Quellcode-Dateien besteht oder auf externe Bibliotheken oder Module zugreift, werden diese in dieser Phase miteinander verknüpft. Dadurch entsteht ein vollständiges ausführbares Programm.
Nach Abschluss dieser Phasen entsteht ein ausführbares Programm, das auf dem Zielcomputer ausgeführt werden kann. Der Kompilierungsprozess ist für die Entwicklung von Software unerlässlich, da er den Quellcode in eine Form umwandelt, die von der Hardware verstanden wird. Dies ermöglicht es Entwicklern, Programme für verschiedene Plattformen und Architekturen zu erstellen.
Fehlerbehebung in der Kompilierung: Gängige Probleme und Lösungen
Die Kompilierung von Quellcode ist ein komplexer Prozess, der oft mit verschiedenen Herausforderungen und Fehlern verbunden ist. Hier sind einige gängige Probleme, die während der Kompilierung auftreten können, und mögliche Lösungen:
- Syntaxfehler: Dies sind Fehler, bei denen die Syntaxregeln der Programmiersprache nicht eingehalten werden. Der Compiler gibt normalerweise eine Fehlermeldung aus, die auf die betreffende Zeile im Quellcode hinweist. Die Lösung besteht darin, den Code entsprechend den Syntaxregeln anzupassen.
- Semantikfehler: Semantikfehler treten auf, wenn der Code zwar syntaktisch korrekt ist, aber dennoch fehlerhaft funktioniert. Dies kann auf falsche Variablenzuweisungen, ungültige Berechnungen oder inkorrekte Verwendung von Funktionen zurückzuführen sein. Diese Fehler erfordern oft eine gründliche Überprüfung des Codes, um die Ursache zu finden und zu beheben.
- Undefinierte Referenzen: Wenn im Code auf Variablen oder Funktionen zugegriffen wird, die nicht zuvor definiert wurden, tritt ein Fehler auf. Die Lösung besteht darin, sicherzustellen, dass alle Verweise auf korrekte Deklarationen verweisen und dass die richtigen Header-Dateien oder Bibliotheken eingebunden sind.
- Kompatibilitätsprobleme: Bei der Kompilierung von Code auf verschiedenen Plattformen oder mit verschiedenen Compilerversionen können Kompatibilitätsprobleme auftreten. Dies erfordert häufig Anpassungen im Code oder die Verwendung von plattformspezifischen Direktiven.
- Speicherlecks: Speicherlecks entstehen, wenn im Code dynamisch Speicher allokiert wird, aber nicht ordnungsgemäß freigegeben wird. Dies kann zu unerwünschtem Speicherverbrauch führen und die Stabilität des Programms beeinträchtigen. Speicherlecks müssen durch sorgfältiges Management von Speicherzuweisungen behoben werden.
Fehlerbehebung während der Kompilierung erfordert oft Geduld und gründliche Kenntnisse der Programmiersprache sowie des Compilerverhaltens. Die Fähigkeit, Probleme zu identifizieren und effektive Lösungen zu finden, ist für Entwickler von entscheidender Bedeutung, um qualitativ hochwertige und zuverlässige Software zu erstellen.








